解决方案介绍
深度卷积神经网络(CNN)算法是深度学习领域普遍采用的神经网络构建模型,Caffe是目前最快的CNN架构。Caffe计算框架正是切中当下深度学习的迫切需求,它采用MPI技术对Caffe版本进行数据并行优化,该框架基于伯克利caffe架构进行开发,完全保留原始caffe架构的特性。即:纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口等多种编程方式,具备上手快、速度快、模块化、开放性等众多特性,为用户提供了最佳的应用体验。另外,鉴于众多用户基于CPU进行深度学习应用研究的现实,我们还可提供C-G算法迁移增值服务,针对用户目前的深度学习算法,做硬件适配性算法迁移和升级优化,帮助用户做到算法的更快,更好。硬件架构:IB网络+GPU集群+Lustre并行存储。
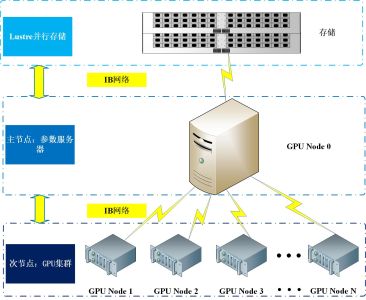
深度卷积神经网络(CNN)算法是深度学习领域普遍采用的神经网络构建模型,Caffe是目前最快的CNN架构。Caffe计算框架正是切中当下深度学习的迫切需求,它采用MPI技术对Caffe版本进行数据并行优化,该框架基于伯克利caffe架构进行开发,完全保留原始caffe架构的特性。即:纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口等多种编程方式,具备上手快、速度快、模块化、开放性等众多特性,为用户提供了最佳的应用体验。另外,鉴于众多用户基于CPU进行深度学习应用研究的现实,我们还可提供C-G算法迁移增值服务,针对用户目前的深度学习算法,做硬件适配性算法迁移和升级优化,帮助用户做到算法的更快,更好。硬件架构:IB网络+GPU集群+Lustre并行存储。
以铠沙AM4280&AM5468为代表的GPU服务器的产品,在同CPU计算力下, GPU配置数量比业内平均水平高出50%,且最高支持的单卡计算能力比业内主流水准高50%,根据深度学习多并行,高I/O需求,设计出Lustre分布式并行存储系统和56Gb/s InfiniBand网络架构的横向扩展的GPU主从硬件集群架构,实现了跨多节点的数据并行计算,该架构兼顾计算密集型,IO密集型等计算模型硬件需求特点,同时支持Pascal GPU,最大可实现超100个GPU卡并行计算。
客户收益
企业通过图像识别技术,建立物体、场景、人脸、着装、文档图片、视频内容等识别&搜索综合系统,通过多维度解读图片内容,挖掘数据价值,使产品运营团队更好地描绘用户画像,帮助企业实现更精准的营销推送,内容审核,大数据挖掘。
广泛应用于各类电商平台,视频直播平台,在线教育平台,大幅度提升产品&内容运营团队效率。在无人驾驶,家庭机器人,无人机,现实增强等前沿应用上提供嵌入式智能后台,以更加智能化的数据利用方式,增加用户粘度,扩展应用维度,激发更具想象力的用户体验。